
Préparer son catalogue à la transition bibliographique
Introduction
Notre projet se situe en amont de tout ce qui a fait le thème de cette journée. Pour jouer avec les métadonnées, encore faut-il en avoir et qu’elles soient assez présentables pour sortir dans le monde, faire des admirateurs, stimuler de nouveaux usages. Et il faut ne pas avoir à les retoiletter tous les jours non plus.
Notre objectif est ici de faire un retour d’expérience sur un projet qui a porté sur le catalogue de la Bpi, donc un catalogue très similaire à celui de nombreuses bibliothèques de lecture publique, volume excepté peut-être : 420.000 notices bibliographiques actives (notices d’imprimés, de films, documents multi support, bases de données, captations vidéo….).
Autre point commun avec la majorité des bibliothèques françaises, l’Unimarc est notre format de production et d’échange. Pour restructurer nos données, il était donc incontournable de nous réapproprier ce format, lequel est souvent maltraité dans nos SIGB, il est tronçonné, filtré, méconnaissable derrière des bordereaux et masques de saisie si bien qu’il est rarement mis en œuvre dans toute sa richesse.
C’est pourtant un format
-qui met en jeu des référentiels au niveau des données codées (par exemple iso 639.2 pour les codes de langues) tout comme au niveau des accès (Rameau)
-qui est capable de gérer les liens entre enregistrements et qui peut embarquer également les identifiants des enregistrements liés
-qui évolue pour rendre compte du modèle FRBR et de RDA. Les nouvelles zones 181 & 182, ne sont que les premières pierres d’une révision de plus vaste ampleur
Enfin, comme pour toute bibliothèque, la grande affaire de la Bpi est la valorisation de ses collections et de ses services et le premier vecteur en est la qualité et l’ergonomie de son catalogue public avec tout l’enjeu que constitue la qualité des données. Et nous attendions d’un tel projet un bénéfice rapide sur notre catalogue public.
Ce préambule pour souligner combien ce qui va suivre pourra, nous l’espérons, aider au montage d’autres projets de ce type avec une ampleur facilement aménageable (couverture courante; rétrospective, champ d’application sur les notices bibliographiques/ notices d’autorité, …).
Toutes les fonctionnalités qui seront présentées sont disponibles dans notre base de production depuis fin juin 2016. Elles ont été développées dans notre SIGB Portfolio par la société Bibliomondo.
Contexte Bpi
Insularité du catalogue
La Bpi ne fait pas partie d’un réseau de catalogage. Au démarrage du projet, on y dérivait peu de notices bibliographiques et aucune notice d’autorité
Les notices de la base Electre servaient et servent encore d’ailleurs, de notices de commande.
Sur le graphique ci-dessous figure le résultat d’un bilan fait sur l’origine des notices bibliographiques pour l’année 2010. En vert les notices créées ex nihilo, en jaune les notices de commande enrichies par la seule Bpi et en violet et mauve les notices enrichies par la dérivation de notices de la BnF
Etat des lieux en 2010 : TABLEAU des sources de catalogage courant sur l’année 2010
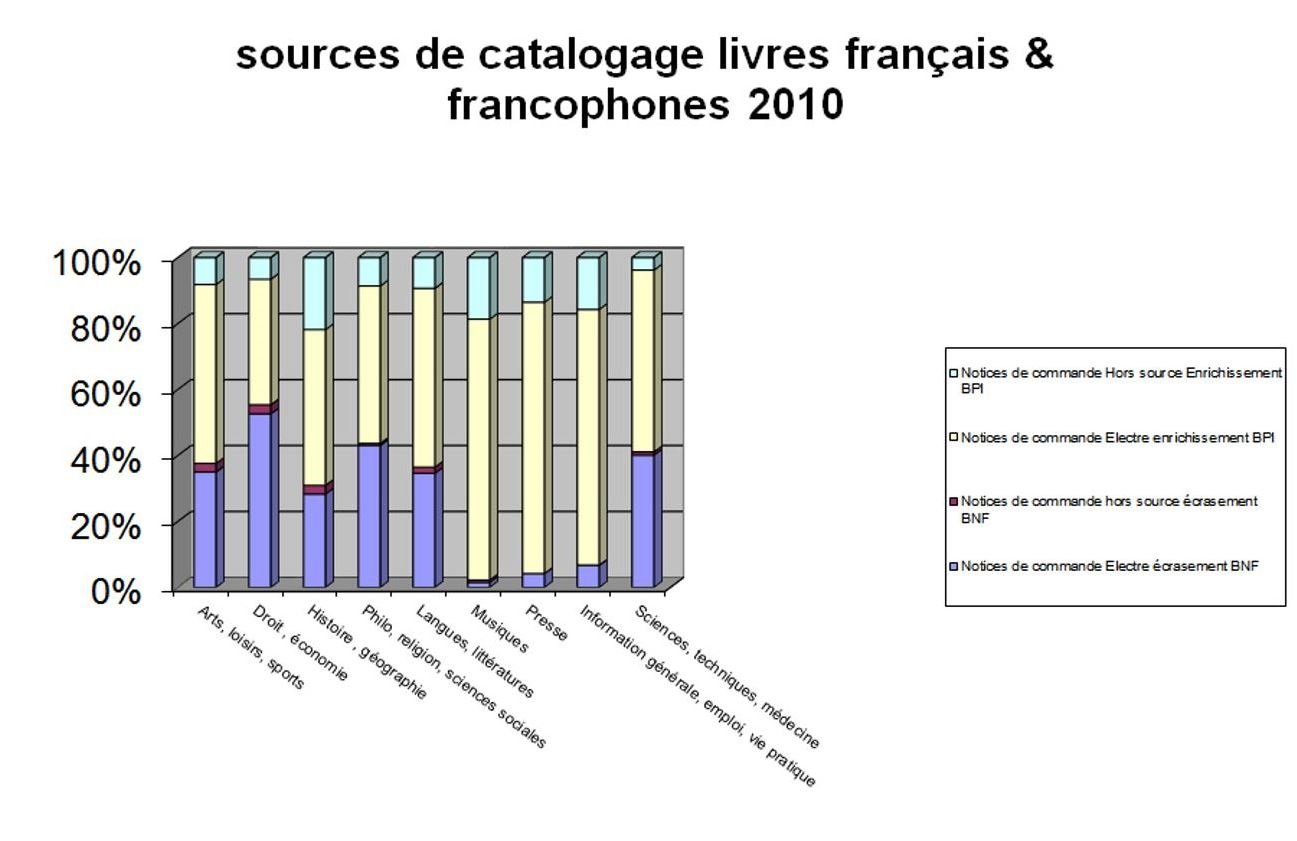
Comme on le voit, la marge de progression est considérable.
Organisation du traitement documentaire
Pas de service de catalogage centralisé
Les chargés de collection suivent les documents de la commande jusqu’à la mise en rayon en passant par le catalogage et l’indexation et ils sont également chargés de leur valorisation et, de l’autre côté de la chaîne, de leur désherbage.
On en déduira facilement qu’il n’y a pas une grande technicité en catalogage ni non plus un temps important à consacrer à cette activité. A contrario, le chargé de collection détient des connaissances de son domaine et de ses collections lui permettant de ménager des accès complémentaires (indexation matière, public destinataire, accès auteurs…).
Ce sont également les chargés de collection qui établissaient des notices d’autorité sommaires, lesquelles étaient ensuite enrichies au niveau de notre service en s’inspirant des notices de la BnF, mais sans dérivation.
Un service support
Notre service Données et accès administre les outils de production et l’interface publique. Dans le versant “production” de notre service, on compte l’administrateur du SIGB et trois coordinateurs des autorités, dont un en charge du plan de classement.
Un réseau de référents traitement
Pour faire le relais entre les services de collection et ce service support a été mis en place un réseau de référents traitement à la refonte de l’organigramme qui a coïncidé avec le début du projet. Il y a un référent pour chacun des 11 services de collection de la Bpi. La fonction de référent traitement est mentionnée sur les fiches de poste qui ont été établies à cette époque avec un bonheur variable. Ce qui est acquis toutefois, c’est un référent par service de collection, interlocuteur et relais du Service Données et accès (il y a à la Bpi 11 services thématiques).
Objectifs du projet : deux grands axes d’amélioration
Une organisation à améliorer
Aux origines du projet, nous n’avons pas dissocié la correction des données de l’amélioration de l’organisation car nous voulions garantir à la fin du projet, en production courante, la qualité des données.
Le premier objectif était de mettre en place les conditions d’une meilleure coordination bibliographique. Jusque-là, nos deux coordinateurs des données d’autorités concernés intervenaient en bout de chaîne sur des autorités créées sommairement par les chargés de collection. Dans les faits, ces coordinateurs ne disposaient ni des outils ni du temps nécessaires pour intervenir autrement que sur des petits faisceaux de notices. Ils remontaient les erreurs, dénouaient les liens erronés au hasard des nouvelles créations. Tout cela au détriment d’une vraie fonction de coordination bibliographique.
Le second objectif, à mi-chemin entre organisation et simple sensibilisation ou recadrage, était de clarifier le rôle de chacun dans la chaîne de la donnée et de bien isoler la production des données et leur exposition
Bon nombre de chargés de collection avaient pris l’habitude de cataloguer en fonction de l’affichage sur le catalogue public; c’était là le résultat d’un long compagnonnage avec un OPAC lié au SIGB, ce qui était le cas jusqu’il y a trois ans encore (nous avons désormais un catalogue public développé en propre où nous récupérons et alignons les données issues du sigb et les données d’autres bases externes ou internes pour les exposer de façon fédérée).
Cette habitude prise par les chargés de collection résulte aussi de la faible perception des enjeux du respect des formats dans un catalogue longtemps fermé sur lui-même et étranger à toute problématique d’alignement ou tout échange de notices à quelques exceptions près (comme le Catalogue national des films).
Des données à améliorer
Côté données, on imagine bien que l’état des lieux n’était guère enthousiasmant.
Des données incomplètes
Notamment dans les blocs de liens et de titres associés.
Mais aussi dans le bloc des données codées en 1xx où les données étaient peu renseignées ou pas corrigées lorsque les notices étaient dupliquées ou recyclées.
Des adaptations maison du format Unimarc
On relevait aussi des données locales présentes dans les zones standards mais ces adaptations n’étaient pas identiques d’un service de collection à l’autre.
Des données hétérogènes
Le résultat était des données hétérogènes, présentant des strates chronologiques et des strates de services ou de supports.
Axe 1 : conforter la chaîne du traitement documentaire
Favoriser la récupération de notices bibliographiques et d’autorités
Le choix a été fait de conforter l’organisation du traitement documentaire de la Bpi : dans les services de collection, consolider une fonction de dérivation de notice (avec expertise bibliographique minimale pour identifier la bonne notice) et conforter un travail original pour la saisie de données complémentaires majoritairement des points d’accès contrôlé, des métadonnées, cette part du travail que nous allons nommer la “valeur ajoutée Bpi”.
Le fait de n’avoir pas touché à l’organisation relevait à la fois d’un pragmatisme et d’une conviction : l’organisation Bpi, à condition de recadrer les attributions de chacun, était la plus adaptée à la bibliothèque avec un enrichissement assuré au plus près des collections d’une part et d’autre part des fonctions de contrôle et d’harmonisation déportées sur un service support.
Il fallait donc privilégier l’ergonomie des récupérations de notices et le contrôle des données entrées. Cette première fonctionnalité à destination des chargés de collection et la seconde pour le service en charge de l’administration des données.
Pour la récupération de notices, notre cible prioritaire, “institutionnelle”, a été la BnF.
Coordonner et harmoniser les ajouts de métadonnées complémentaires
Nous devions également coordonner, harmoniser les ajouts de métadonnées complémentaires en leur trouvant une zone Unimarc standard et en mettant en place/à jour des référentiels internationaux ou dans certains cas faute, de mieux en créant des référentiels internes à la Bpi sur zones de données contrôlées (nous avons par exemple instauré un accès genre en Rameau et établi une liste contrôlée maison sur le public destinataire)..
Axe 2 : assurer les évolutions à venir
Préserver/conforter la richesse des données
Rendre nos données plus propres ne signifiait pas pour nous pas comme on l’a vu appauvrir l’existant mais plutôt l’ouvrir et l’enrichir en lui permettant de dialoguer avec les bases bibliographiques de référence.
Il nous fallait introduire dans les notices tous les identifiants des notices BnF correspondantes, enrichir ou corriger les notices Bpi au moyen des notices de la BnF et mettre en place des procédures pour maintenir cette concordance dans le cadre du catalogage courant.
Il nous fallait introduire dans les notices tous les identifiants des notices BnF correspondantes, enrichir ou corriger les notices Bpi au moyen des notices de la BnF et mettre en place des procédures pour maintenir cette concordance dans le cadre du catalogage courant.
Garantir les évolutions des interfaces
Nous avons fait le choix d’enrichir les notices de la Bpi avec les notices BnF de la manière la moins sélective possible : les données non exploitées sur l’actuelle interface pourraient l’être en effet dans une prochaine version ou dans 10 ans, pourquoi pas? Quelle importance y a-t-il à les stocker bien au chaud dans nos notices?
Avoir un différentiel trop faible entre le périmètre des données exposées et celui des données produites ou dérivées signifie soit qu’on a une très bonne interface soit qu’on pratique une récupération de notices trop strictement ajustée au contexte d’exposition immédiat, une récupération trop sélective.
Notre leitmotiv : appuyer l’évolution de notre interface publique sur ces données plus riches et permettre une meilleure adaptation aux usages de nos lecteurs mais aussi ménager des marges d’évolution en décorrélant la production de données de leur exposition : avoir des données plus riches que celles qu’on exploite réellement et ne pas faire de choix exclusif de récupération de zones lors de dérivation de notices qui soient trop strictement ajustés au contexte d’exposition immédiat.
Garantir les évolutions du modèle de description bibliographique
Ce choix garantit également de s’adapter aux évolutions du modèle : les codes de fonction, bon nombre d’autres données codées ou bien encore les zones de liens sont souvent mal exploités sur nos interfaces actuelles et donc négligés en production; ils permettent pourtant de décrire ou de consolider des relations fondamentales dans le modèle FRBR.
En attendant de pouvoir permettre à nos usagers de s’approprier ces données ou de les exposer nous-même aux moteurs de recherche…
Travaux préparatoires sur les données du catalogue
En préalable aux imports de notices BnF, des travaux préparatoires ont été menés : analyse des pratiques, mise à jour des formats Unimarc, ménage dans les notices, et enfin préparation des autorités en vue de leur alignement avec celles de la BnF.
Analyse des pratiques
Pour commencer, nous avons organisé une phase d’analyse des pratiques, appelée « recueil des données » : lors de réunions avec les référents traitement et des collègues des services de collection, il s’agissait de décrire les pratiques de catalogage en vue de leur harmonisation. Nous avons relevé les aménagements faits dans le format, repérer les zones standard comprenant des informations locales pour les déplacer. Le but était de redonner aux zones leur usage standard tout en identifiant les valeurs ajoutées Bpi, qui ne se retrouvent pas dans les notices d’autres sources (exemples : public destinataire, genres littéraires) et seront à protéger.
Le compte-rendu a été fait sous forme de tableau de synthèse : on notait ainsi les caractéristiques du format standard, les usages Bpi et BnF. Nous faisions enfin pour chaque zone une proposition d’exploitation : déplacer des données, protéger ou non la zone, établir des listes contrôlées.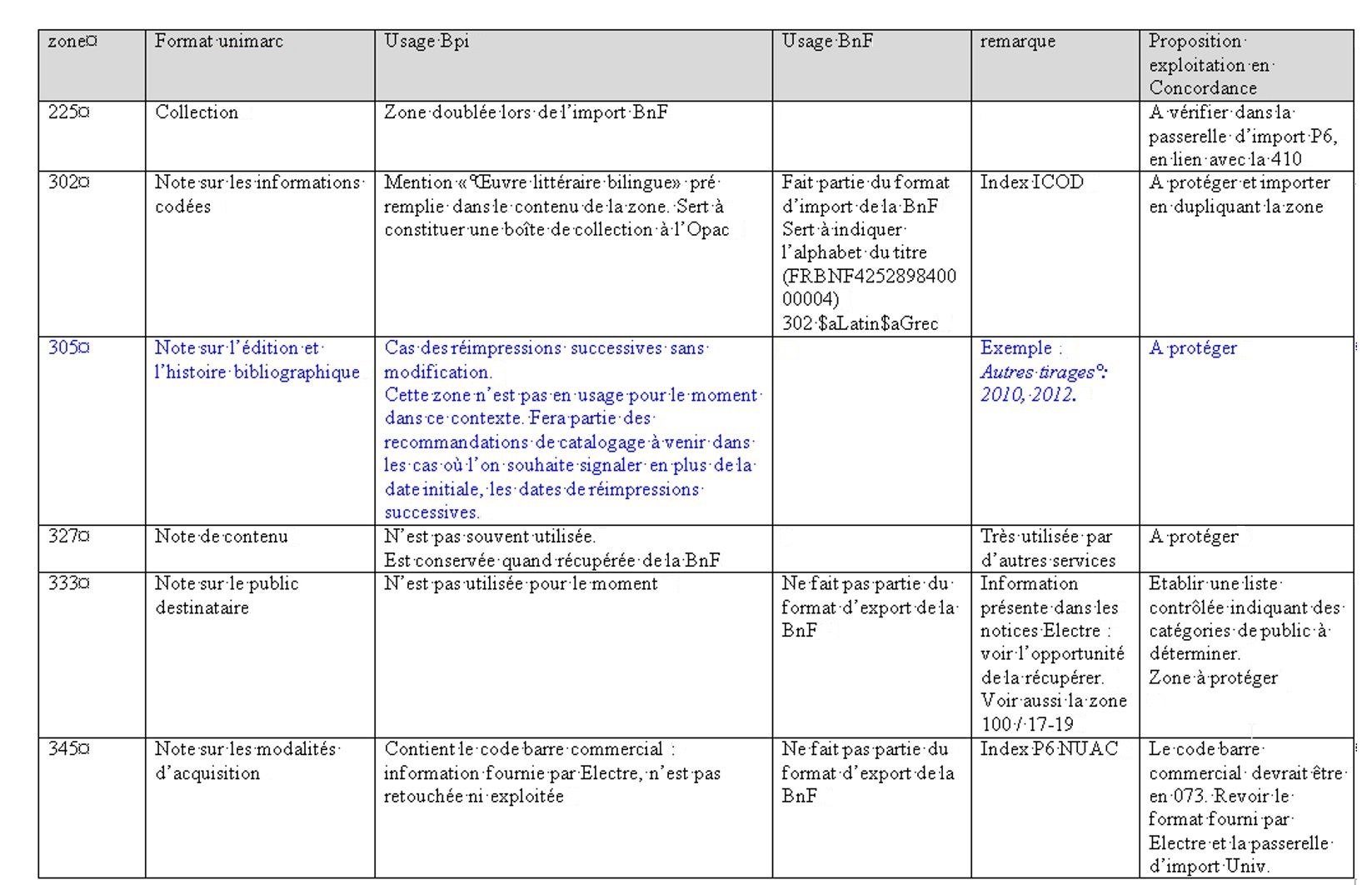
Mise à jour des formats Unimarc
Pour assurer ensuite la conformité de nos données avec le format standard, il a été nécessaire de mettre à jour les formats Unimarc à l’intérieur de notre SIGB. Ce travail a été mené à la fois pour le format bibliographique et autorité.
Pour ce faire, nous nous sommes appuyés sur les formats Unimarc standards et sur le format de diffusion des notices fournies par la BnF. En effet, pour pouvoir importer de manière satisfaisante les données d’une source externe, il faut que les zones Unimarc du SIGB aient les mêmes caractéristiques que celle de la source de récupération.
Le fait de prendre en compte le format de diffusion de la BnF a occasionné quelques légères adaptations du format standard. Par exemple, dans certaines zones des notices BnF une barre verticale remplace les valeurs standards des indicateurs. Nous intégrons cette donnée à notre paramétrage des zones de manière à ce que la présence des barres verticales ne génère pas d’erreur dans les notices importées. Au moment du catalogage, ces valeurs sont laissées telles quelles, nous ne demandons pas aux chargés de collection de rétablir les valeurs standards. (Notre SIGB détecte certaines erreurs formelles dans les notices et attribue selon les cas un niveau d’erreur qui est interrogeable).
La mise en conformité du format Unimarc dans notre SIGB a été menée conjointement avec des déplacements de données dans des zones plus appropriées suite au relevé effectué lors du recueil des données (exemple : déplacement des mentions de dépouillement présentes en 545 vers les zones 464 ou 469, plus adaptées à cet usage).
Il a aussi été nécessaire de mettre à jour les modalités de validation des zones soumises à autorités dans le SIGB, ainsi que les index permettant d’interroger les zones Unimarc ajoutées ou modifiées.
Ménage dans les notices
Une fois la structure Unimarc mise en place, nous avons fait du ménage dans nos notices. Il s’agissait de réduire la masse de notices à traiter pour ne garder que celles réellement en usage.
Pour les notices bibliographiques, cela a donné lieu à un léger dépoussiérage : nous avons supprimé les scories et les spécimens les plus étranges (61 045 notices supprimées, soit 14% de nos notices bibliographiques).
Pour les autorités, nous avons supprimé celles qui n’étaient pas liées à des notices bibliographiques (162 516 notices supprimées, soit 40% de nos anciennes autorités).
La nouvelle base de travail après nettoyage était donc de 430 000 notices bibliographiques et 264 695 autorités.
Préparation des autorités
Nous avons ensuite traité prioritairement les autorités car c’était les notices qui présentaient le plus d’écart par rapport au format standard.
Pour repérer les différents cas et les quantifier, nous leur avons ajouté des marqueurs dans une zone locale interrogeable. Nous avons fait appel à notre prestataire pour le repérage des notices concernées. Cela a facilité la correction majoritairement automatisée de ces notices.
Exemple : les noms de famille (marqueur FAM) :
Bpi : Zone 200 $aMuller$cfrères ; verriers = Zone 600 ou 700 de la notice bibliographique
BnF : Zone 220 $aMuller (frères ; verriers) = Zone 602 ou 72X de la notice bibliographique
Le même problème s’est posé pour les autorités auteur-titre et titre uniformes musicaux.
Pour faciliter le travail d’harmonisation des pratiques, la création et la modification d’autorités ont été reprises uniquement par notre service. Dans le traitement courant, les pratiques de description ont été repensées dans la perspective de l’import des notices BnF. Pendant une période intermédiaire, nous avons privilégié l’insertion des numéros FRBNF dans nos autorités et procédé à des récupérations d’autorités de la BnF par paniers sur son catalogue, en attendant l’import massif qui allait suivre.
Alignement des autorités Bpi avec celles de la BnF
Après cette étape de correction, nos autorités avaient repris leur emplacement standard. Nous pouvions alors tenter de les aligner avec celles de la BnF.
Les alignements ont été faits avec le concours de la BnF (via les outils de data.bnf) et de notre prestataire Bibliomondo.
L’objectif était de comparer nos notices avec celles de la BnF et d‘insérer le numéro FRBNF dans nos notices (en zone 035).
Ce numéro nous servira ensuite comme clé de mise à jour lors de l’import.
Nous avons choisi d’aligner nos autorités pour conserver les liens faits vers celles-ci dans nos notices bibliographiques (les liens se font par reconnaissance de caractères dans notre SIGB).
Il y a eu une faible part d’alignements manuels pour des cas où les données étaient trop disparates et donc difficiles à traiter de manière automatique (moins de 1% de nos autorités).
Exemple :
Noms de souverains, papes, saints
Bpi : $aLouis$croi ; France ; 14
BnF : $aLouis$dXIV$croi de France$f1638-1715
En ce qui concerne les alignements automatisés, une première série a été fournie via les outils de data.bnf. Nous avons fait parvenir à la BnF nos autorités par fichiers. Celles-ci ont été comparées aux autorités BnF par les outils de data.bnf. La BnF nous a ensuite retourné des fichiers d’alignement sous forme de tableaux de correspondances entre notre numéro d’identifiant local et le numéro FRBNF.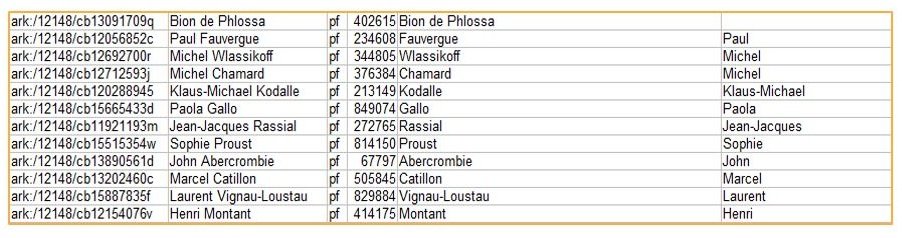
Une 2e série d’alignements a été réalisée par notre prestataire. Nous avons utilisé notre base de test, comme un bac à sable, en y versant l’intégralité des autorités BnF. Le prestataire a ensuite lancé une recherche de doublons entre nos notices et celles de la BnF et cela a donné lieu à de nouveaux alignements.
Ces alignements ont été faits par notre prestataire en dehors des outils du SIGB par des développements spécifiques.
Les correspondances issues de ces deux séries d’alignements ont enfin été versées en base de production. A ce stade, il ne s’agissait pas encore d’importer les notices de la BnF mais simplement d’insérer les identifiants dans nos notices. Cette démarche nous a permis d’aligner 70% de nos autorités (les 30% qui restent nécessitent une analyse et un traitement qui est toujours en cours).
Les imports
Les identifiants : pivots des imports
Comme les imports ont pour objectif de mettre à jour nos notices, les identifiants ont un rôle essentiel. Ils servent en effet de clé de mise à jour.
Pour les notices bibliographiques, il s’agit essentiellement de l’ISBN et pour les autorités du numéro FRBNF présent en 035.
Pour les notices bibliographiques, il s’agit essentiellement de l’ISBN et pour les autorités du numéro FRBNF présent en 035.
Des choix techniques différents pour les notices d’autorités et les notices bibliographiques
Nous avons fait des choix techniques différents pour les autorités et les notices bibliographiques.
Pour les autorités, nous utilisons les produits BnF, avec un import initial de plus de 2 millions de notices, suivi de mises à jour mensuelles. Il n’y a pas de protection de zones Bpi lors de l’import, nos autorités sont entièrement mises à jour.
Pour les notices bibliographiques, nous avons choisi de travailler de manière plus sélective en utilisant le protocole Z39.50. A l’import, les notices passent par des filtres qui permettent de protéger certaines données Bpi.
Nous avons fait ce choix pour les notices bibliographiques car notre fonds ne correspond qu’à une partie des notices BnF. Il nous paraissait donc lourd de charger l’ensemble des notices bibliographiques BnF : modéliser un fonctionnement avec vendangeur à l’intérieur même du SIGB était plus complexe compte tenu de la masse de données à traiter et du fait que nous avons déjà des notices en réservoir (Electre) qui servent à passer les commandes.
La BnF était pour nous une première source de récupération et nous voulions aussi développer des outils utilisables pour d’autres sources. La solution basée sur le protocole Z39.50 nous paraissait plus adaptable dans ce contexte.
Nous avons deux outils de récupération : l’un est utilisé par les chargés de collection au moment du catalogage livre en main en constituant des paniers de notices. Cet outil est fonctionnel pour les chargés de collection en traitement courant. Le second est prévu pour traiter des lots de manière plus automatique et en grande masse. L’objectif est notamment d’assurer une fonction de monitoring sur les notices non trouvées au moment du catalogage livre en main.
Pour sécuriser cette récupération automatisée, plusieurs contrôles sont effectués : dans le lot constitué par équation, le système recherche des doublons et les exclut du processus. Les notices sont ensuite recherchées dans le catalogue de la BnF : si des doublons sont trouvés dans les notices BnF, ceux-ci sont également exclus. Seules les notices ayant une correspondance de un à un (une notice Bpi = une notice BnF) sont importées.
La fonctionnalité de mise à jour par lots est fonctionnelle mais n’a pas été mise en œuvre à grande échelle pour le moment. Seuls 13% de nos notices bibliographiques comportent un identifiant BnF, la marge de progression est donc importante.
Raffinement des options d’import
Une des conclusions du “recueil des données” est que nous avions besoin de possibilités de filtrage des données plus fines au moment de l’import. Cela a fait l’objet d’évolutions dans notre SIGB avec de nouvelles fonctionnalités livrées par notre prestataire.
Pour les notices bibliographiques, nous disposons de nouvelles options de protection des zones Bpi, en particulier celle permettant à la fois d’importer et de conserver une zone. Nous l’utilisons par exemple pour les zones d’indexation matière : cela nous permet de conserver notre indexation matière tout en important celle de la BnF si celle-ci est différente.
Pour les autorités, des développements ont été nécessaires afin d’assurer une mise à jour satisfaisante des notices, notamment pour le cas des notices supprimées à la BnF. Il s’agit alors pour nous de désactiver les autorités concernées et d’annuler les liens dans les notices bibliographiques.
Nouveaux outils de veille qualité
Afin de pérenniser l’amélioration de nos données, nous nous sommes dotés d’outils de veille : ceux-ci ont pour but de mieux repérer les erreurs et de pouvoir les corriger plus facilement.
Rapports d’erreurs et de doublons
Nous avons maintenant la possibilité d’éditer des rapports sur la base d’équations de recherche pour détecter des erreurs et des doublons. Les critères de repérage sont très fins et permettent d’identifier des zones précises et des types d’erreur.
Les rapports de doublons sont disponibles à la fois pour les notices bibliographiques et les autorités.
Les rapports sont dynamiques : on peut afficher dans le SIGB les notices ainsi repérées et intervenir en correction. Des outils de modification en lot sont également reliés à cette nouvelle présentation des résultats. On peut aussi afficher les notices côte à côte ce qui est très utile dans le cadre du traitement des doublons.
Correction et fusion avancées
Pour corriger plus finement les doublons, une fonctionnalité de fusion avancée a été développée : elle permet de transférer sur la notice à conserver des informations présentes dans la notice à supprimer.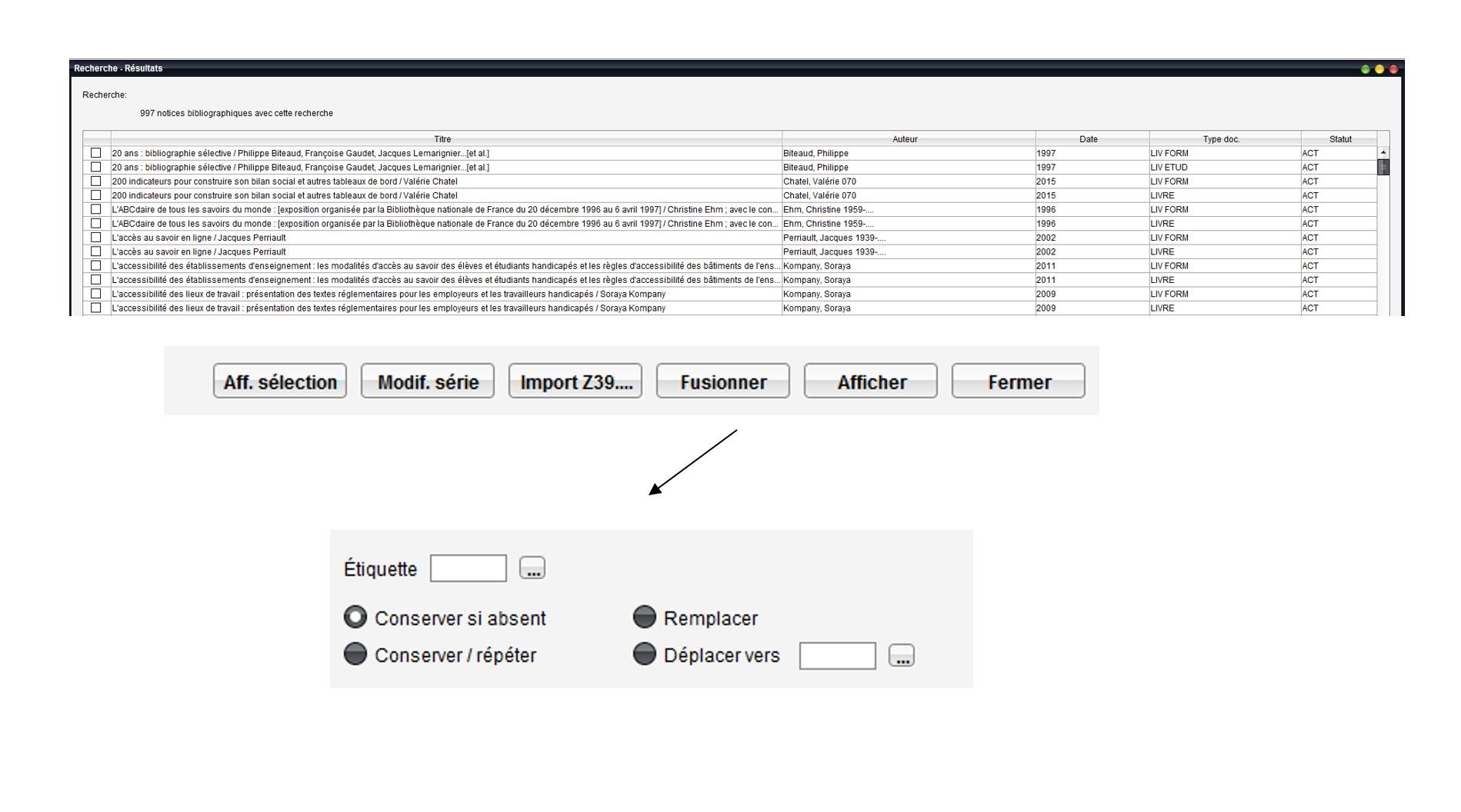
Comparaison de notices
Enfin nous disposons d’un outil visuel de comparaison de notices : il nous permet d’afficher dans un rapport des informations qui habituellement ne sont pas visibles simultanément dans le SIGB, ou qui nécessiteraient beaucoup de clics et de manipulations pour y accéder.
Cela permet de relever des incohérences dans les données.
Par exemple : comparer les indices CDU présents dans les notices bibliographiques et les cotes des exemplaires.
Les conditions de réalisation
Des bases solides
Une équipe de projet stable
Côté Bpi, nous avons opté pour un co-pilotage qui intégrait les deux dimensions indissociables du projet : la production et l’exposition des données (l’administration du sigb et la modélisation des données sur l’interface).
Nous avons bénéficié d’un renfort considérable pour les tests, les corrections et les formations en la personne des deux coordinateurs des autorités concernés.
Côté prestataire nous avons eu la chance d’avoir sur tout le projet un développeur dédié même si nous avons changé plusieurs fois de chef de projet.
Un accompagnement des services et des évolutions tout au long du projet
Dans la mesure où il touchait la base de production, la structuration des liens et la structuration des notices, ou bien encore l’établissement des accès, le projet a impacté le traitement courant à chaque phase de sa réalisation.
Un des volets important du projet a été l’accompagnement au changement : mise en place d’un dialogue avec les équipes via leurs relais référents traitement, communication régulière sur l’avancée du projet et les impacts sur le traitement, montage de sessions de formation pour l’ensemble des services de collections à mi-parcours pour les autorités et en fin de parcours pour les nouveaux outils de récupération.
Ceci perdure avec une intervention renforcée de notre service dans le programme de formation des nouveaux arrivants qui existe à la Bpi dans le premier mois de la prise de poste et un rendez-vous mensuel thématique à l’intention des services de collection sur les problématiques liées au catalogue Les ateliers du catalogue ( la première session a eu pour thème Naviguer à la source des notices avec pour objectif d’apprendre à lire une notice, sa provenance, sa structure, …).
Un soutien administratif et hiérarchique
Un soutien administratif pour le suivi budgétaire et le suivi du marché.
Un soutien hiérarchique indispensable :
– pour la validation du fonctionnement en mode projet avec toutes les implications des multiples aléas d’un projet sur le suivi courant.
– pour que notre rôle de coordination soit reconnu dans la mesure où l’on perd souvent beaucoup de temps et d’énergie sur des coordinations ou des pilotages sans lien hiérarchique. C’est le problème récurrent des services supports.
Partage et dialogue
Un dialogue constructif avec le prestataire du SIGB
Nous avons établi les grands principes dans des spécifications générales intégrées au cahier des charges du marché Concordance et à chaque phase du projet, nous avons établi des spécifications détaillées en dialogue avec l’équipe projet Bibliomondo (ce qui a amené à adopter des solutions techniques plus réalistes par rapport notamment aux capacités techniques du SIGB ou à ses principes de fonctionnement interne). Ceci suppose une souplesse pour que des solutions différentes soient adoptées tout en restant ferme sur les grands principes.
Dans un projet de cet ordre, il fallait laisser part à la créativité intégrant une dimension de « heureux hasard ». On peut parler à ce titre d’une co-construction avec le prestataire.
Un partage avec notre communauté professionnelle
Enfin, nous avons été confortés dans nos choix à l’occasion de participations à des journées étude comme celle-ci et ou via notre participation au groupe national RDA en France devenu programme national Transition bibliographique. Cela nous a permis de valider nos options, trouver des sources d’inspiration, rester motivées dans notre projet et l’inscrire dans une perspective plus vaste d’évolution des catalogues.
A suivre
Des données en chantier, des chantiers de données
Un meilleur service rendu par notre service en matière de coordination bibliographique
L’amélioration des outils de suivi permettra de se concentrer sur le renforcement et la facilitation de la valeur ajoutée Bpi : maintien de la liste contrôlée du public destinataire, travail rétrospectif sur les accès genre,…
Un autre grand axe est la poursuite des formations ou de l’accompagnement aux chargés de collection sur les autorités et les accès avec le montage d’ateliers thématiques.
Nous entendons également assurer une veille sur tout autre contexte de données hétérogènes, pour lesquelles la nécessité de référentiels se ferait sentir. En un mot, nous aurons la possibilité enfin d’anticiper les besoins de signalement des chargés de collection.
De nombreux chantiers de correction en perspective
Il nous faut circonscrire des chantiers de correction, mettre en place des processus de veille qualité et des processus de traitement grâce aux nouveaux outils de la Concordance.
Une nouvelle version du catalogue public
La nouvelle version du catalogue public est actuellement en chantier. Les données exposées seront en Dublin core qualifié et, conséquence directe du projet Concordance, nous allons exposer nos notices d’autorités. Cela sera l’occasion d’expérimenter dans notre catalogue public les liens entre différents types de notices, ce que nous ne faisions pas dans l’actuelle version, puisque nous intégrions les données biblio et d’exemplaires “à plat” à partir d’une table source unique.
Elargissement du périmètre
Évolution de l’outil de comparaison de la Concordance
Nous projetons une évolution de l’outil de comparaison de la Concordance avec des critères de comparaisons reposant sur des similitudes et non plus seulement de stricte identité de zones.
D’autres sources pour le catalogue
Nous nous intéressons à IdRef pour les autorités et au SUDOC, dont nous comptons intégrer les notices de périodiques correspondant à nos collections sur la base des identifiants PPN.
Les perspectives plus lointaines
Par ce projet, la Bpi a atteint son objectif de favoriser la récupération optimale des données de la BnF et a adossé ainsi son catalogue sur la production d’une agence bibliographique nationale porteuse de l’évolution vers les nouveaux modèles.
Il lui faudra toutefois garantir cette concordance sur la durée et suivre l’évolution du format Unimarc et la publication du code RDA-FR.
Sylvie Lemaire : sylvie.lemaire[at]bpi.fr
Karine Meneghetti : karine.meneghetti[at]bpi.fr
site web Transition bibliographique
Publié le 02/12/2016 - CC BY-SA 4.0
Sélection de références
Transition bibliographique
Le site officiel : présentation et actualité du programme Transition bibliographique