
Appartient au dossier : Projets de sémantisation et cartographie des collections
Prototype pour la sémantisation de la classification de la Bpi
Lors d’un stage effectué en 2022, Alexandre Couturier, alors élève conservateur de l’Enssib, a mis en place un premier prototype de sémantisation des données de la classification de la Bpi.
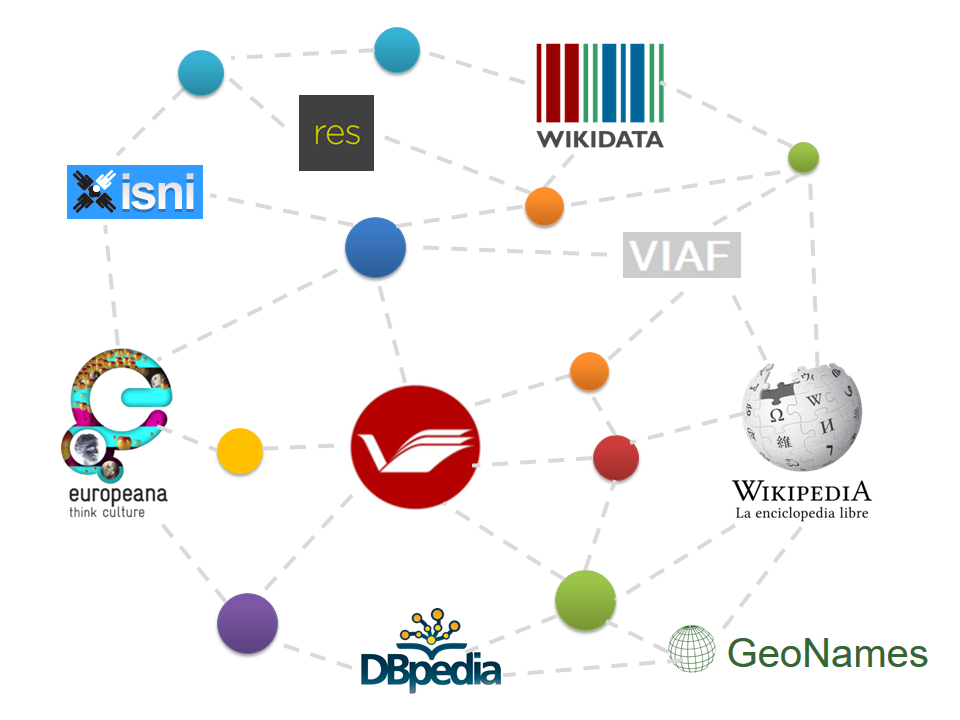
L’objectif était de réaliser une preuve de concept (POC) de la modélisation de la classification selon les nouveaux formats du web sémantique, en évaluant la faisabilité de cette démarche pour obtenir un premier outil de transformation des données et réfléchir à leur usage possible. Dans cet article, Alexandre revient sur l’ensemble des travaux menés au cours de son stage.
Contexte du projet
Depuis plusieurs années, les équipes de la Bibliothèque publique d’information travaillent à l’amélioration de l’interface du catalogue pour le rendre plus accessible, mais aussi sur des chantiers de correction des données.
L’un de ces projets, nommé « Concordance », a engagé l’établissement à ouvrir son catalogue vers des sources de données extérieures, en particulier vers le catalogue général de la Bibliothèque nationale de France (BnF). Afin de pouvoir aligner ses données avec celles de la BnF, la Bpi s’est mise en conformité avec les formats standards (Unimarc et référentiels liés) et intégré les identifiants ark uniques propres à la BnF dans ses notices. Ces identifiants permettent aujourd’hui de faire automatiquement le lien avec les données produites par la BnF, mais aussi de suivre et intégrer leurs évolutions. Le projet Concordances a fait l’objet de plusieurs présentations dont le verbatim d’une intervention et un article sur l’accompagnement au changement mis en place pour ce projet.
Le projet Concordance était donc la première brique pour faire émerger de nouveaux modèles de données bibliographiques, en faisant évoluer substantiellement les manières de décrire les collections de la Bpi, offrant ainsi des résultats de recherche plus pertinents aux usagers.
Ces questions, que recouvre en France le programme national de la Transition bibliographique, ne présentent pas les mêmes enjeux pour une bibliothèque de lecture publique de l’importance de la Bpi. Concrètement, la Transition bibliographique consiste à adopter les formats de données standards du web pour décrire les collections et ainsi les rendre plus facilement indexables par un moteur de recherche.
Ces évolutions induisent également une nouvelle interprétation des données (une « sémantisation ») en permettant de multiplier des liens, aujourd’hui inexistants dans le format Unimarc. Il peut s’agir, par exemple, de lier un ouvrage et son adaptation cinématographique ou encore les différentes traductions d’une œuvre entre elles.
Pour se familiariser avec les nouveaux modèles de données du web sémantique, la Bpi a décidé de travailler à partir de septembre 2022, à titre prospectif, sur un jeu de données assez bien circonscrit.
Une première expérimentation autour du web sémantique
Un premier projet sous forme de preuve de concept (POC), consistait en une modélisation des données de la classification des collections en libre accès, et leur transformation pour faciliter leur exposition sur le web. Plusieurs caractéristiques de la classification de la Bpi ont conduit à la choisir comme jeu de données initial à modéliser.
Il s’agit :
- D’un jeu de données original, qui bien qu’inspiré de la CDU, est produit et administré par la Bpi ;
- D’une classification riche du fait de son caractère encyclopédique et des possibilités de construction d’indices thématiques complexes avec des subdivisions ;
- D’un formalisme bien établi avec des notices d’autorité composées d’un nombre de champs Unimarc limité ;
- D’un lot clairement délimité et d’une volumétrie modérée.
Il s’agissait donc sur ce corpus de données de créer une chaîne de traitement fluide, avec un exemple de portail d’exposition.
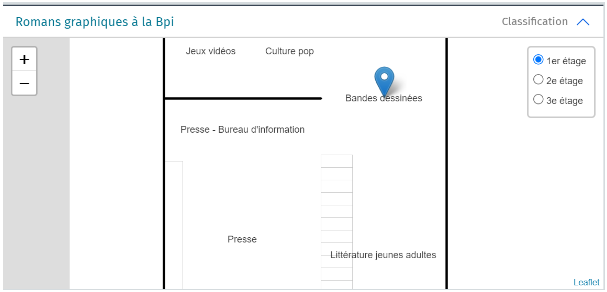
Le cas d’usage prévu pour l’exploitation des données de la classification était de concevoir un outil de navigation dans une cartographie des collections de la Bpi. Cette application devrait faciliter l’appropriation des collections en libre accès dans un contexte où l’établissement changera de lieu et de configuration dans les prochaines années, du fait de la fermeture du Centre Pompidou pour travaux à partir de 2025.
Cette expérimentation, exclusivement réalisée en interne, a permis à l’équipe du Service données et accès (SDA) et aux collègues du Département des systèmes d’information (DSI) de repérer les compétences utiles à une mise en œuvre à plus grande échelle et de se familiariser techniquement avec le web sémantique. Nous proposons ici de faire un récit des différentes étapes nécessaires à la poursuite de cet objectif.
Analyse des données à sémantiser
Avant toute chose, il est important de bien connaître les données manipulées, en particulier leur plus-value pour les utilisateurs, leur structuration mais aussi les droits qui leur sont associés.
La classification de la Bpi, inspirée de la Classification décimale universelle (CDU) est véritablement propre à l’établissement, ce qui constitue un gisement de données assez original. Elle sert à la fois de plan de classement des collections dans les espaces et de classification intellectuelle. Tous les ouvrages et documents physiques de la Bpi sont associés à un indice alphanumérique qui existe dans le SIGB sous forme de notice d’autorité Unimarc possédant un identifiant unique et des zones hors de tout standard ISBD.
En décembre 2022, ce sont ainsi 45 776 notices qui structurent l’ensemble des collections de la Bpi et permettent d’envisager bien des manières de les parcourir, au-delà de ce que permet aujourd’hui le catalogue public.
Ce projet a également été l’occasion de réaliser un diagnostic sur la structuration des données, ainsi que sur certains aspects intellectuels de la classification, en particulier la cohérence de la hiérarchie entre les indices.
Élaboration du modèle de données
Après avoir évalué la pertinence des données à disposition, il convient d’élaborer un nouveau modèle de données reprenant les principes du web sémantique. Le web sémantique permet véritablement d’inscrire des données dans le web et plutôt que d’uniquement les mettre en ligne.
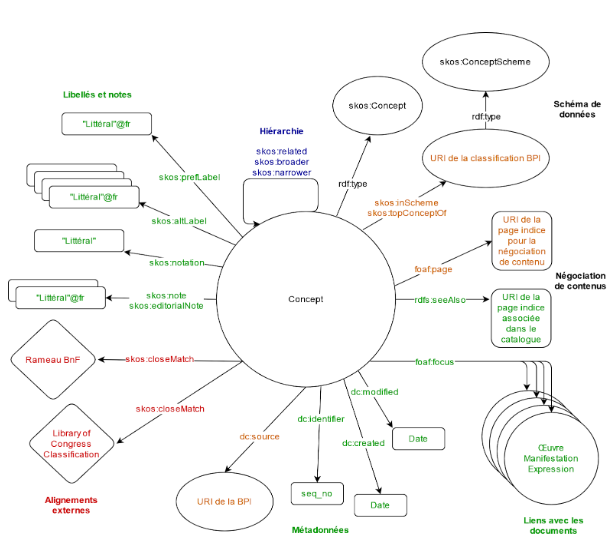
Il s’agit, dans notre cas, de prendre comme concept central la notion d’indice de classification et, pour chacune des zones Unimarc associées à cet indice, de caractériser (c’est-à-dire de donner un sens ou de sémantiser) la relation à cette donnée. Plutôt que d’indiquer simplement que la zone Unimarc 453$a de la notice de l’indice « 756 Peinture africaine » a pour valeur « Afrique (peinture) », on explicite le lien entre l’indice et cette valeur. En langage naturel, on pourrait donc dire « L’indice « 756 Peinture africaine » a pour forme rejetée de libellé « Afrique (peinture) » ».
On forme ici une phrase sous la forme d’un sujet, d’un verbe (ou prédicat) et d’un objet, ce qu’on appelle un triplet. Le format standard pour décrire des triplets est le Resource Description Framework (RDF), qui a des syntaxes multiples, mais peut s’écrire dans sa syntaxe la plus simple (syntaxe Notation3) :
| <Sujet> | <Prédicat> | <Objet> . |
| <http://site_d’exposition_de_nos_données/ classificationBPI/identifiant_unique_de_ l’indice> | <http://www.w3.org/2004/ 02/skos/core#altLabel> | “Afrique (peinture)” . |
Pour caractériser la relation entre un indice, exprimé par un URI (Identifiant de Ressource Uniforme) unique, et la forme rejetée de son libellé, exprimée par une chaîne de caractères, on a donc recours à un prédicat lui aussi exprimé sous la forme d’un URI. En l’occurrence, pour décrire des vocabulaires contrôlés, comme des thésaurus ou des classifications, de nombreux prédicats peuvent par exemple être empruntés à un vocabulaire très utilisé, le Simple Knowledge Organization System (SKOS).
Ainsi, si l’on tente de représenter toutes les relations qui correspondent aujourd’hui à des zones Unimarc de la notice indice, on peut par exemple dessiner un graphe qui emploie des prédicats au vocabulaire SKOS (voir le diagramme ci-dessous).
D’autres choix sont possibles, notamment l’usage de vocabulaires plus précis, comme le Metadata Authority Description Schema in RDF (MADS/RDF) établi par la bibliothèque du Congrès. Il existe également des vocabulaires spécifiques aux bibliothèques, à l’instar de l’ontologie Resource Description and Access (RDA) et sa déclinaison française, RDA-FR pour étendre la modélisation aux données bibliographiques.
Processus de transformation des données
Une fois un modèle de données défini, il convient véritablement de transformer les données.
À partir du modèle de données, est établi un mapping qui décrit les correspondances entre les zones Unimarc et les prédicats et objets des triplets. La zone 253$a par exemple est traduite en un prédicat skos:PrefLabel explicitant une relation entre un indice et son libellé.
Parfois ces données doivent être nettoyées, reformatées voire subdivisées lorsque les zones Unimarc contiennent une information complexe et multiple, notamment pour interpréter la ponctuation présente dans les indices. Aussi, certaines informations parfois inexistantes nécessitent d’être reconstituées, c’est le cas par exemple de la hiérarchie entre les indices de la classification qui peut être déduite grâce aux règles de la CDU.
Techniquement, ces données, une fois extraites de l’entrepôt de données du SIGB, sont manipulées au format CSV grâce à des scripts codés en langage Python.
Ces données sont enfin transformées en triplets RDF grâce à l’installation locale de l’outil xls2rdf. Le format de sortie est un fichier Turtle (une autre syntaxe légère du RDF). L’objectif à ce stade est d’automatiser au maximum la transformation de données afin de faciliter la création des triplets et leur mise à jour régulière et rapide.
Stockage et visualisation des données sémantisées
Afin de pouvoir exposer ces données, il faut d’abord les stocker dans une base de données adaptée aux triplets en RDF appelée triplestore. Du fait de la taille réduite du corpus, le choix s’est porté sur la solution Apache Jena Fuseki.
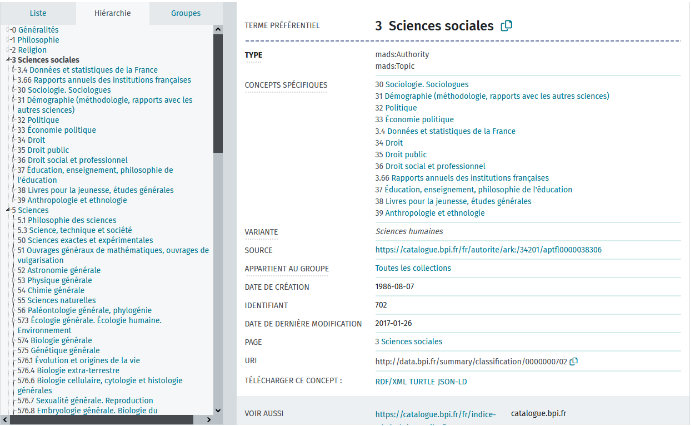
Dans le cadre de ce projet, l’exploration en ligne de la classification de la Bpi a aussi nécessité l’installation de l’outil clé en main Skosmos, une interface web qui exploite les données stockées dans le triplestore (voir la capture d’écran ci-dessous). Il s’agit plus précisément d’un navigateur et outil de publication SKOS web et open source développé pour les besoins de la bibliothèque nationale finlandaise. Cet outil est particulièrement adapté pour l’exposition de vocabulaires contrôlés comme des classifications ou des thésaurus. L’outil permet de naviguer aisément dans la classification, de télécharger les données dans divers formats et de créer de très nombreux liens vers d’autres ressources, des documents par exemple.
Surtout, l’intérêt de la modélisation et de l’exposition de ces données est de permettre d’envisager une réutilisation facilitée pour des acteurs extérieurs, mais également pour la Bpi elle-même. L’exemple pris dans le cadre de ce projet est un prototype de cartographie des collections en libre accès. Dans l’optique des déménagements successifs de la bibliothèque, l’orientation des lecteurs et leur autonomie vis-à-vis des collections est un enjeu d’importance. Durant ce stage ayant pris fin en décembre 2022, l’outil de cartographie n’a pu être proposé qu’à un stade embryonnaire.
Conclusion et perspectives
Après cette première expérimentation, l’objectif à court terme est l’industrialisation des chaînes de traitement des données afin de permettre des mises à jour régulières et facilitées de toute la classification. La création d’une véritable cartographie des collections est l’autre priorité actuelle.
Si un tel projet démontre la faisabilité de recourir aux technologies du web sémantique et de cheminer progressivement vers de nouveaux modèles de données, plusieurs défis se posent aux bibliothèques qui veulent s’investir dans ce genre de projets. D’abord la nécessité de s’acculturer à ces modèles qui sont non seulement techniques mais impliquent aussi de repenser notre façon de décrire nos collections et nos données. Ensuite, la multitude des possibilités d’alignement et d’enrichissement offertes par l’ouverture au web de données implique de mener une réflexion sur l’usage de ces données et la plus-value que l’on souhaite apporter à nos usagers.
Dans le cadre de cette preuve de concept, la question de l’alignement et de l’enrichissement des données est restée largement théorique et n’a pu jusqu’à présent être mise en œuvre. En l’état, cela paraissait un travail très chronophage, car en partie manuel sur un grand nombre de données. L’évolution récente des capacités des modèles d’intelligence artificielle permettra peut-être à l’avenir d’effectuer ces alignements de manière assistée.
Alexandre Couturier,
Responsable adjoint du département des services au public,
Bibliothèque de l’université Paris-8-Vincennes – Saint-Denis
Publié le 22/10/2024 - CC BY-SA 4.0