
Appartient au dossier : Le nouveau catalogue public de la Bpi
Le nouveau catalogue public de la Bpi : chantier de conception
Pour son nouveau catalogue public, la Bpi a conçu un outil unique et sur-mesure.

Le 22 septembre 2020, la Bpi a mis en production une nouvelle interface publique pour son catalogue. S’achevait ainsi le travail de plus de cinq années.
Ce vaste chantier a été suivi par une équipe projet de sept personnes travaillant à la Bpi : quatre bibliothécaires du service Données et accès (Département Lire le monde) et trois développeurs du service Etudes et projets (Département des systèmes d’information). La première partie des travaux, consistant en une refonte complète de l’infrastructure et du mode de récupération des données, a été menée en interne ; la seconde, la conception d’une interface graphique, a été réalisée avec l’intervention d’un prestataire extérieur.
Historique du projet
En 2015, l’obsolescence du catalogue est constatée. S’engage alors un projet visant à le moderniser. Trois objectifs sont fixés : la simplification de la chaîne de données et de l’interface, l’amélioration de l’accès aux ressources électroniques et la mise en conformité du catalogue avec la réglementation de l’accessibilité numérique.
La Bpi hésitant entre un outil standard fourni par un éditeur et une conception sur mesure, une assistance à maîtrise d’ouvrage est demandée. Cette dernière a tranché que, du fait de la singularité de sa collection, la Bpi ne pouvait utiliser un outil clé en main. Un recueil des besoins auprès de collègues de nombreux services a donc été réalisé, afin de définir les points essentiels sur lesquels se concentrer. Puis, en 2016, des ergonomes indépendants ont été sollicités pour fournir des maquettes répondant aux attentes ; l’accessibilité des maquettes a ensuite été validée par un expert accessibilité.
Un travail sur l’infrastructure et le schéma de données
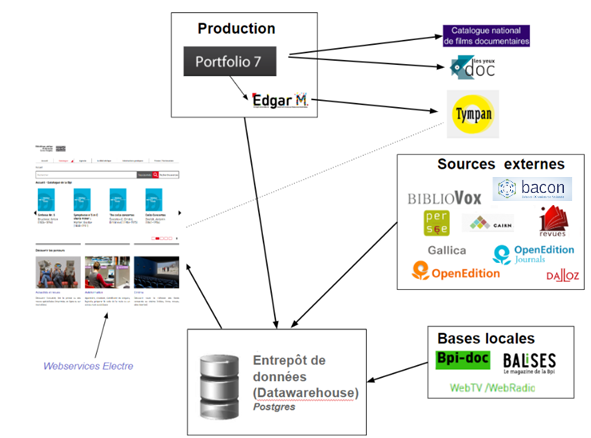
Ce chantier, réalisé entre 2017 et 2019, a été effectué en interne par trois développeurs, à la demande de l’équipe Catalogue public du service Données et Accès. Il a touché l’infrastructure et le schéma de données, soit la partie cachée du catalogue. La précédente version se composait de deux bases de données différentes, d’un logiciel peu fonctionnel servant entre autres pour l’harmonisation des données ou la définition des moissons, et d’un CMS qui n’était plus maintenu depuis plusieurs années. L’infrastructure devait donc être simplifiée, afin de mieux contrôler toutes les étapes et réduire les temps de traitement. Toutefois, la Bpi souhaitait conserver un principe de la version antérieure : le mélange, dans les mêmes tables de la base de données, des notices produites en interne et de celles venant de sources externes, ceci afin qu’elles ressortent uniformément sur l’interface publique. Dans un même temps, elle voulait aussi enrichir et diversifier ces mêmes données.
La simplification de l’infrastructure est passée par le développement d’un unique “moissonneur” multifonctionnel.
Cet outil sert avant tout à la récupération des données internes ou externes, dans une base de données SQL, en s’appuyant sur des mappings entre les champs sources et les champs des tables internes. Le travail a surtout consisté à augmenter la quantité et la variété des données récupérées. Pour les notices internes, davantage de zones et de sous-zones de l’Unimarc ont été isolées dans les tables, permettant un affichage plus précis de certaines données comme la note sur les récompenses, les titres uniformes, les titres en relation, les titres d’ensemble ou les autres éditions. De plus, ont été prises en compte les zones créées ces dernières années pour la mise en place de la Transition Bibliographique [voir article https://pro.bpi.fr/preparer-son-catalogue-a-la-tran/] : la zone de l’adresse 214, la forme du contenu 181 et le type de médiation 182. En parallèle, des pré-filtrages ont été installés pour écarter les notices inactives ou incomplètes. Pour les notices externes, des champs ont été prévus pour récupérer spécifiquement des données OAI ou Kbart.
Ce moissonneur a aussi permis de diminuer la durée des collectes, et de diversifier les formats et donc les sources : dans la précédente version, seules les données OAI pouvaient être moissonnées ; à présent, ont été ajoutées les données issues de fichiers Kbart – et prochainement, celles via Json et via Onyx. Le bon déroulement de ces actions est contrôlable depuis un back-office, mais aussi grâce à des alertes et des reportings réguliers.
Au sein du moissonneur, les données sont également traitées. Ainsi, les notices présentes dans les entrepôts ou fichiers externes qui ne font pas partie des abonnements contractés par la Bpi sont filtrées grâce à un module d’exclusion. D’autre part, les données sont partiellement transformées : les intitulés des langues, des supports et des types de document sont harmonisés, fonction indispensable pour unifier les données exposées sur le catalogue sachant que les entrepôts et fichiers récupérés utilisent des normes de catalogage et des vocabulaires différents. En outre, un identifiant unique est attribué à toutes les notices Bpi ; cet identifiant est exploité pour construire des ARKs servant d’URL pour toutes les notices détaillées. Ces mêmes types d’identifiants sont établis aussi pour les notices moissonnées pour lesquelles les URL sont des permaliens. Enfin, le moissonneur gère l’indexation des données dans un indexeur Solr, nécessaire à la recherche des documents.
C’est aussi en interne que les différents web-services, qui sont utilisés pour alimenter les résultats de recherche de l’interface publique, et qui retournent les résultats au format XML, ont été développés. Ces web-services répondent spécifiquement à chacun des types de recherche souhaités par la Bpi, en recherche simple et recherche avancée.
Enfin, avec l’aide du service Production informatique (DSI), une authentification unique à tous les sites et applications de la Bpi a été établie, en se basant sur un même annuaire LDAP. Les profils d’accès aux ressources électroniques depuis le catalogue ont aussi été simplifiés, en les restreignant à trois : un profil “interne”, correspondant aux postes fixes virtualisés disponibles pour les usagers au sein de la bibliothèque, qui permet d’accéder à l’ensemble du catalogue et des liens d’accès, un profil “wifi” pour les postes professionnels et les appareils connectés via le wifi interne avec moins de ressources payantes disponibles, et enfin un “externe”, pour tous les postes distants, qui donne toujours accès à l’ensemble du catalogue mais uniquement aux liens des ressources libres.
Travail sur l’interface publique
La seconde partie du chantier, qui a eu lieu en 2019 et en 2020, a consisté à offrir une interface publique au nouveau catalogue. La fourniture et le développement de cette interface, permettant la restitution visuelle des web-services, a été confiée à un prestataire extérieur. Ce dernier était accompagné par un expert accessibilité numérique, tandis que la Bpi travaillait avec un autre prestataire chargé de l’audit de l’accessibilité.
Parmi les exigences techniques, la solution proposée devait être compatible avec les dernières versions des principaux navigateurs du marché (Firefox, Safari, Internet Explorer/Edge et Chrome). Contrairement à précédemment, l’interface ne devait pas non plus dépendre d’un CMS pour l’affichage des données, mais utiliser les langages standards du web. C’est pourquoi, les différentes pages, conçues par la Bpi avec l’aide d’un graphiste indépendant, devaient tout d’abord être livrées au format HTML exempt de tout JavaScript. Nous avons ainsi disposé des patrons des pages, afin de tester la validité des rendus sur plusieurs navigateurs et vérifier leur accessibilité. Ce n’est que dans un second temps que le JavaScript, servant à la partie dynamique du site, a été ajouté. Enfin, après validation de tout le graphisme, le code a été rédigé en PHP permettant de gérer les appels aux web-services et l’authentification aux comptes utilisateurs. La conception du site s’est étalée sur dix-huit mois, et se poursuit, après la mise en production de l’interface, pour des évolutions et de la maintenance. Chaque étape du développement a été validée par la Bpi à la suite de points projet avec le prestataire et a subi une expertise d’accessibilité. La procédure d’intégration a été documentée et approuvée en partenariat avec la direction du DSI de la Bpi. De plus, avant la mise en production, il y a eu un transfert d’expertise : la société a livré le site à la Bpi laquelle a, à présent, la main sur l’ensemble des éléments qui le composent.
Durant les mois qui ont précédé sa mise en production, l’interface a été testée par des utilisateurs bibliothécaires internes, des usagers de la Bpi et des utilisateurs accessibilité, afin d’avoir des retours sur les différentes fonctionnalités et sur l’ergonomie de cette interface. Un accompagnement des utilisateurs a aussi été mis en place, peu après la mise en production, avec des formations pour les collègues de la bibliothèque et des permanences pour présenter la nouvelle interface aux usagers.
Publié le 30/11/2020 - CC BY-SA 4.0